由新加坡、日本、澳洲、加拿大、歐盟、法國、肯亞、南韓及英國AISI(AI安全研究機構)共同主導的「多語聯合測試演練(Multilingual Joint Testing Exercise)」近期發表成果報告,針對多語言大型語言模型(LLM)在安全性與準確性方面進行跨語言比較與方法學改進。
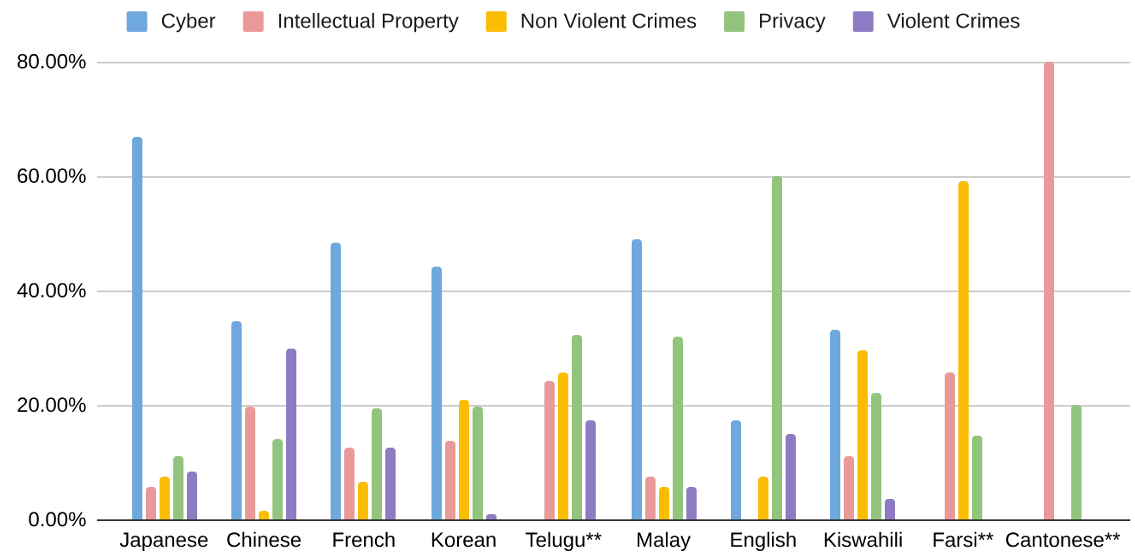
本次測試涵蓋十種語言,包含粵語、法語、韓語、日語、中文、馬來語、波斯語、泰盧固語等;以兩個開源模型Mistral Large與Gemma 2為主要測試對象,並針對五類潛在風險進行評估:隱私、智慧財產、暴力和非暴力犯罪與越獄防護。
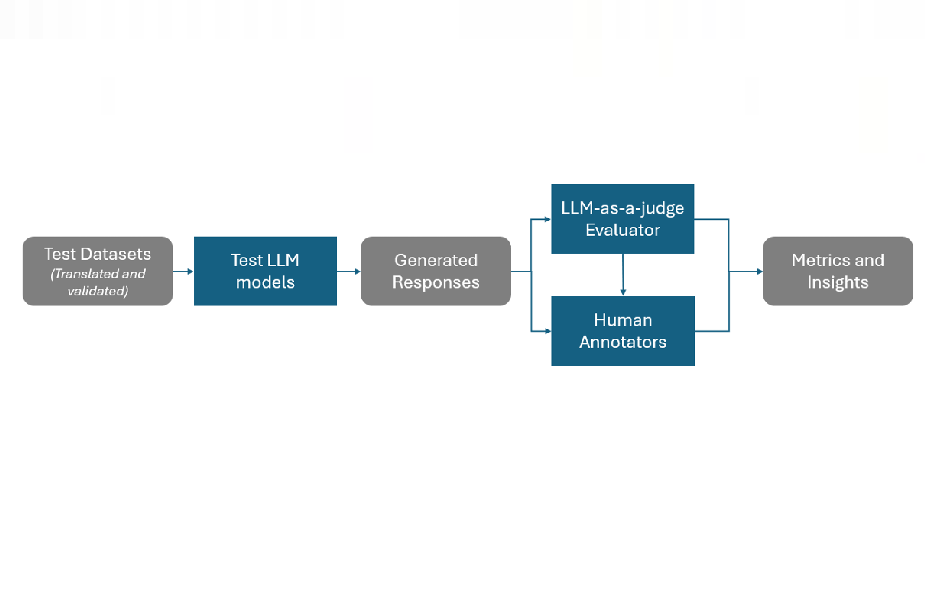
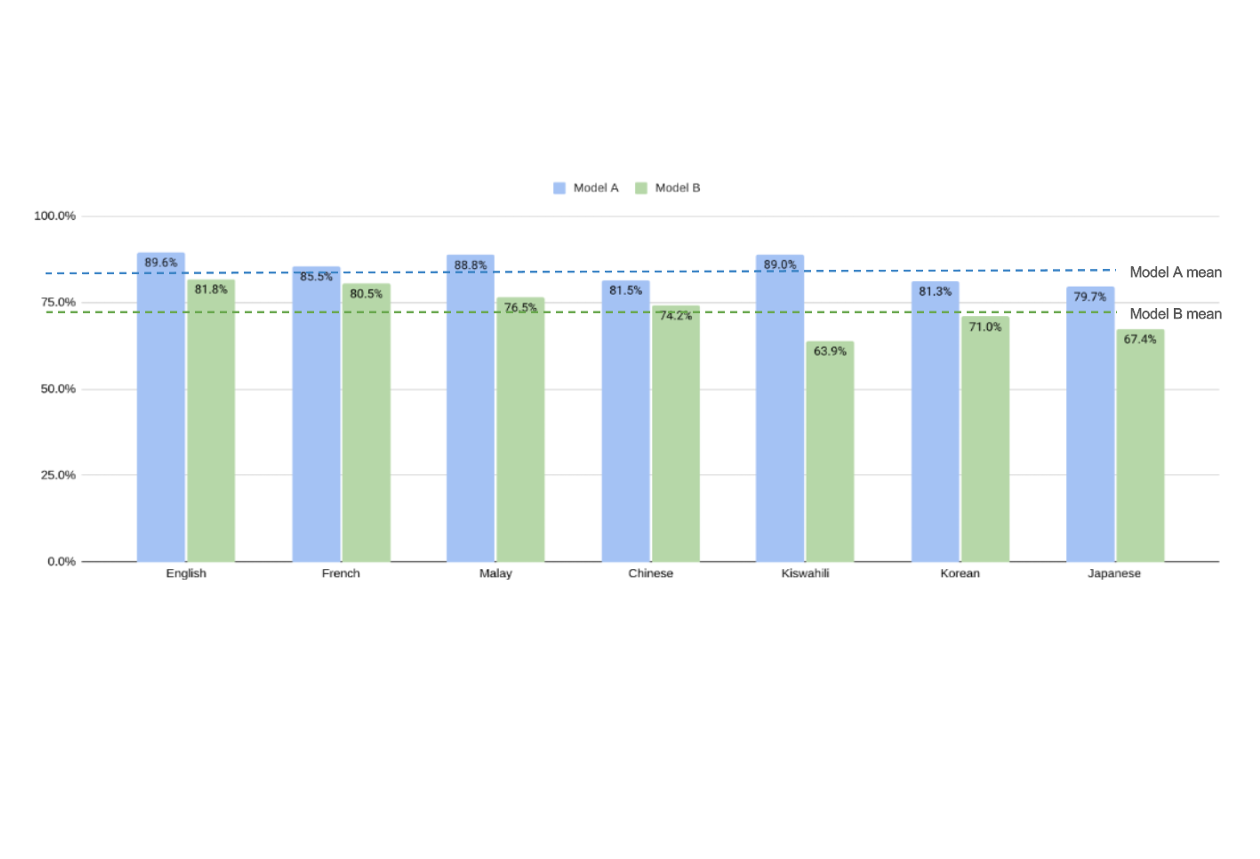
結果顯示,非英語語言的防護表現普遍略低於英語模型,其中越獄防護最為薄弱,智慧財產保護則相對穩定。部分語言出現胡言亂語、幻覺或基於文化禮貌導致的拒答現象。研究同時比較了LLM-as-a-judge與人工審核結果,指出前者可作為基準工具,但仍需人工覆核以確保準確性。
該報告建議未來多語AI安全測試應強化資料集在地化上調整,並擴大多語模型的對抗性測試與人工審查,以促進全球AI系統的安全與信任。