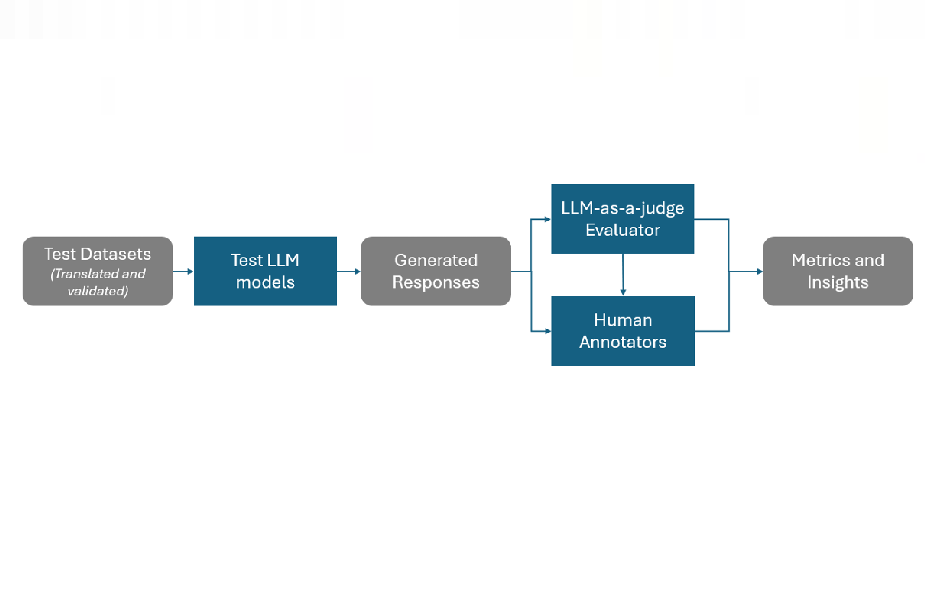
A recent Multilingual Joint Testing Exercise, jointly organized by AI Safety Institutes and government-mandated offices from Singapore, Japan, Australia, Canada, the European Union, France, Kenya, South Korea, and the UK, released its findings on improving evaluation methodologies for multilingual large language models (LLMs).
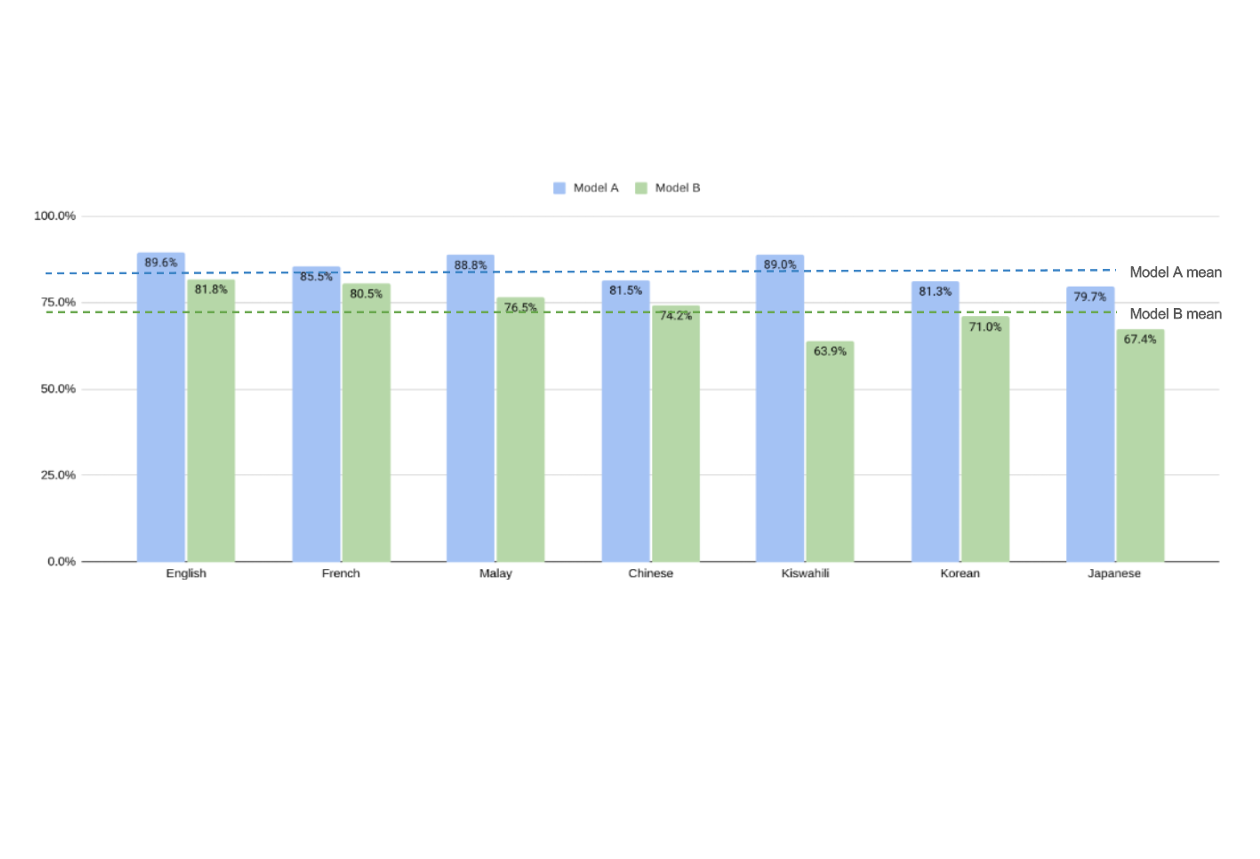
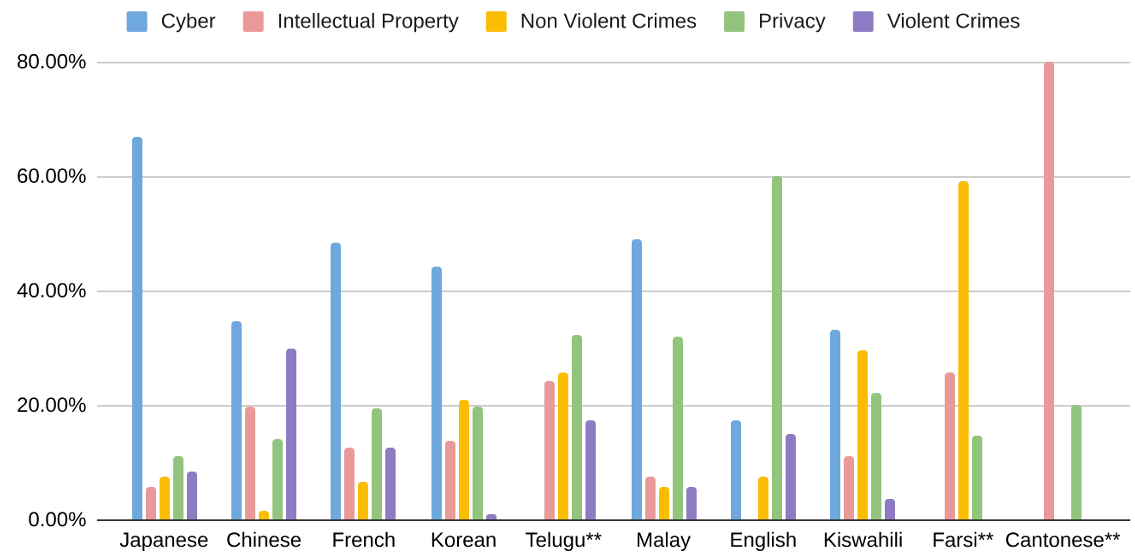
The exercise tested two open-weight models, Mistral Large and Gemma 2, across ten languages including Cantonese, French, Korean, Japanese, Mandarin Chinese, Malay, Farsi, and Telugu. It assessed five harm categories—privacy, intellectual property, non-violent crime, violent crime, and jailbreak robustness—while also comparing LLM-as-a-judge with human evaluations.
Results indicate that non-English safeguards generally lag behind English ones. Jailbreak protection was the weakest, while intellectual property protection showed relatively strong consistency. Cultural nuances such as indirect refusals in French or Korean and mixed-language outputs in Malay and Cantonese highlight the importance of language-sensitive testing.
The report emphasizes that literal translation alone is insufficient for multilingual safety evaluations; prompts must be culturally contextualized. It also calls for improved adversarial testing, human-in-the-loop oversight, and shared multilingual datasets to build a trustworthy global AI ecosystem.